Non-engineer? Read the summary ↓
A regenerative NTN payload carrying a full gNB or gNB-DU is a telecom node you cannot touch. Once operational, it must be patched, upgraded, and maintained like any RAN element, but under constraints that invalidate most terrestrial lifecycle assumptions. Maintaining protocol-level consistency across a live constellation where satellites inevitably run different software revisions, serve overlapping coverage areas, and hand traffic between each other, while you cannot update them all simultaneously, is the defining engineering challenge.
This article uses NR terminology throughout, but the same lifecycle constraints apply to NB-IoT regenerative payloads carrying an eNB. The engineering problem is the same: how do you keep a constellation of telecom nodes current, compliant, and interoperable when you cannot update them all at once?
This article examines what makes software lifecycle management for onboard gNB payloads fundamentally different from terrestrial deployments, and what engineering constraints shape how constellation-wide updates must be designed.
The terrestrial baseline and why it breaks
In terrestrial RAN, gNB software updates follow well-understood patterns: staged rollouts across cell sites, feature flags gating new behavior until validation completes, rapid rollback via redundant boot partitions, and regression suites running against live traffic in canary deployments. The underlying assumptions are generous uplink bandwidth to the node, physical access for recovery, homogeneous hardware within a deployment phase, and the ability to converge an entire cluster to a single software version within hours or days.
A regenerative LEO constellation violates every one of these assumptions. Upload bandwidth is constrained to TT&C link capacity, typically S-band or narrowband Ka-band command links designed for telemetry and housekeeping, not bulk data transfer. A full gNB software image may need to be segmented across multiple passes, with each ground station contact window lasting minutes. Hardware revisions diverge across constellation build phases spanning years. Satellites launched in 2025 may carry different processor architectures or FPGA generations than those launched in 2028, yet must coexist in the same service network. Rollback, while possible in principle, carries risks that terrestrial deployments never face: a failed boot sequence on a satellite with no redundant compute path means loss of the node.
TT&C bandwidth and upload scheduling
The feeder link carrying user-plane traffic is not the same link used for platform management. TT&C command uplinks are bandwidth-limited by design, prioritizing reliability and link margin over throughput. Uploading a software image of tens or hundreds of megabytes over a link provisioned for kilobits-per-second command streams, or the low megabits-per-second rates available on newer platforms, still requires careful scheduling across multiple ground station passes.

Updates cannot be applied on-demand. They must be planned, queued, and sequenced across the constellation. The time from first upload (T0) to last satellite updated (T0+n) depends on constellation size, ground station coverage, and TT&C throughput, but n is measured in weeks or months, not hours. Retransmissions, priority pre-emptions for anomaly management, and conflicts with payload operations extend the campaign further. The update is a campaign, not an event.
The consequence: at any given time during a rollout campaign, the constellation is running mixed software versions. This is not an edge case. It is the steady state for any actively maintained constellation.
Hardware revision divergence
Constellations are manufactured and launched in tranches. Each tranche reflects the compute hardware, FPGA fabric, and peripheral interfaces available at the time of satellite integration, often 18 to 36 months before launch. Over a constellation’s operational life, hardware platforms will diverge. The gNB software must either abstract these differences behind a hardware adaptation layer or maintain parallel build targets per hardware revision.
Critical interfaces and hardware routing are locked at launch and cannot be changed afterward. This places heavy demands on pre-launch validation of both hardware and software, well beyond 3GPP protocol conformance. The satellite’s ability to return to a known-good state after a failed update, and the stability of its boot and recovery paths, must be proven before it leaves the ground.
Once in orbit, each software release must be validated against every hardware revision still operational in the constellation. This creates a combinatorial regression testing problem. A release that uses hardware acceleration available only on newer payloads must degrade gracefully on older platforms. In practice, satellites with different hardware and software revisions are grouped into capability tiers, each serving UE populations matched to their supported features. The ground segment must track these tiers and account for them in mobility and load-balancing decisions.
LEO satellite lifetimes of three to five years provide a natural refresh cycle. Older hardware deorbits and is replaced by newer platforms, which bounds the version divergence window. But within that window, the combinatorial problem remains.
Version coexistence and protocol-layer interaction
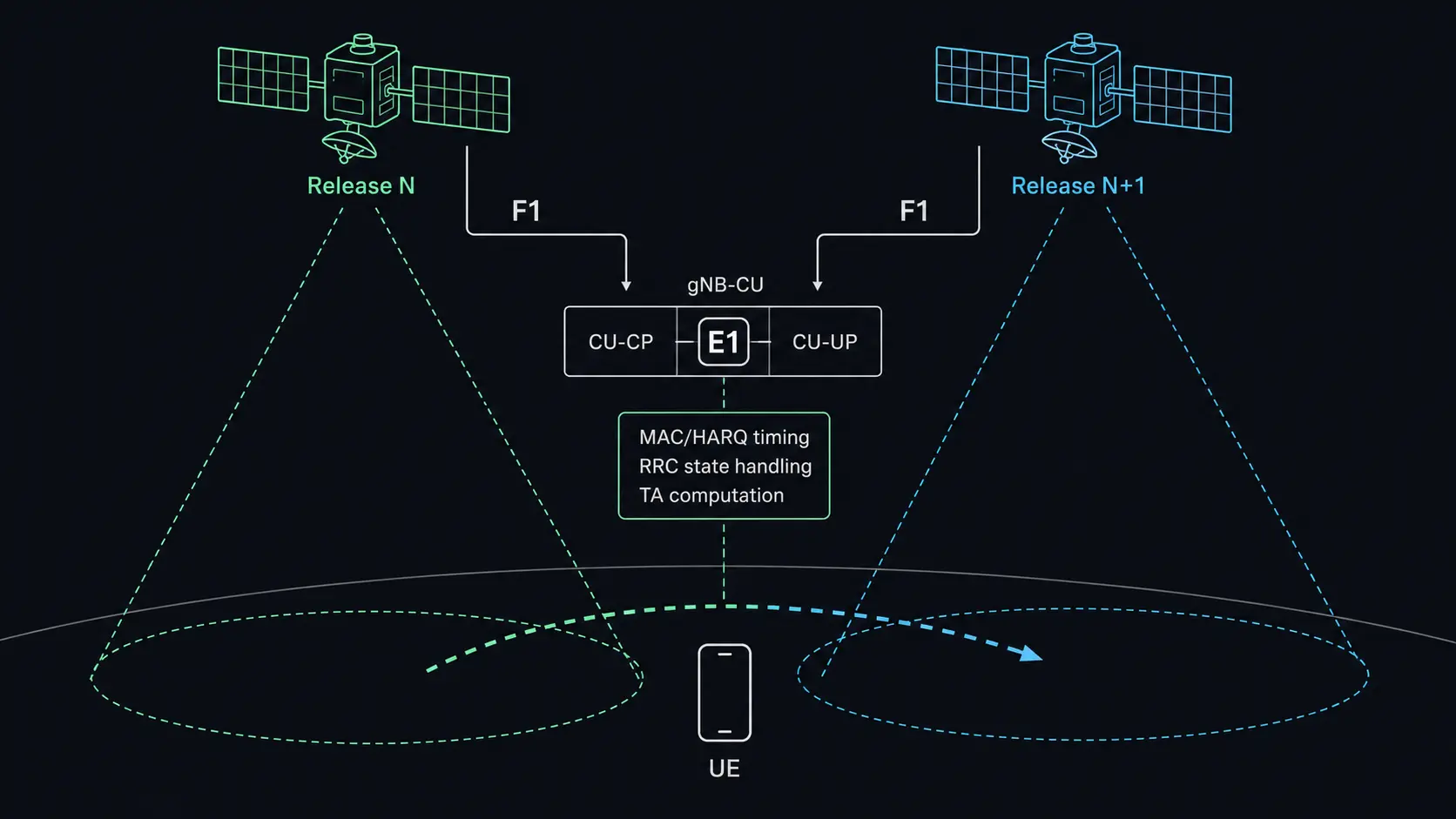
The most consequential constraint is architectural. When two satellites running different software revisions serve the same UE population and participate in inter-satellite or inter-beam handover, three protocol layers are most sensitive to version skew: MAC and HARQ timing, RRC state handling, and timing advance computation. Each creates a different class of problem at the handover boundary.
Consider a UE being handed from Satellite A, running release N, to Satellite B, running release N+1. If release N+1 changed MAC scheduling behavior, modifying how HARQ process counts are managed, adjusting DRX cycle alignment, or altering BSR interpretation, the UE experiences a discontinuity at handover. The RRC reconfiguration message must convey parameters consistent with what the target cell actually implements. If source and target cells disagree on timing relationships, the UE’s state machine may encounter unexpected conditions.
3GPP specifications are designed for heterogeneous environments. Capability exchange during random access and connection establishment allows UEs and network nodes to negotiate supported features, and critical and non-critical extension containers in TS 38.331 let newer IEs be introduced without breaking backward compatibility. Terrestrial networks with multi-vendor nodes face analogous interoperability challenges across different implementations and spec interpretations.
These mechanisms address UE-to-network compatibility, but they solve only half the problem. The UE-facing interface may be spec-compliant in both versions while inter-node behavior differs. If Satellite A’s scheduler assumes one HARQ timing profile and Satellite B’s assumes another, the Xn or F1 signaling between them, or between each and a shared ground-based CU, must accommodate the difference.
For architectures using a ground-based gNB-CU with on-board gNB-DUs, as defined in TS 38.401, the F1 interface becomes the primary version boundary. A CU must maintain compatibility with DUs running different software releases. The E1 interface between CU-CP and CU-UP introduces a second version-sensitive boundary if user-plane handling evolves independently across releases. This problem exists in terrestrial O-RAN deployments, but is far more constrained when you cannot rapidly converge versions. F1AP procedures, UE context management, and bearer setup sequences must remain stable across the version spread present in the constellation at any given time.
HARQ process counts, scheduling algorithms, and feedback timing as specified in TS 38.213 directly affect UE-perceived latency and BLER. NTN-specific adaptations for long RTT, including extended feedback windows and modified process counts, are still being refined across 3GPP releases. Implementations tracking successive releases inherit these changes, making HARQ behavior a persistent source of inter-version divergence.
Modifications to RRC Inactive or RRC Connected state management, or to measurement reporting and handover trigger thresholds, affect mobility performance across the constellation. A satellite with more aggressive handover thresholds will behave differently as a source cell than one running a conservative configuration, even if both remain spec-compliant.
NTN timing advance computation depends on satellite ephemeris and UE position estimation. If a new release refines TA computation, improving Doppler pre-compensation or adjusting the common TA broadcast in SIB, UEs transiting between old and new satellites see a step change in TA handling at handover.
Rolling updates, feature gating, and rollback
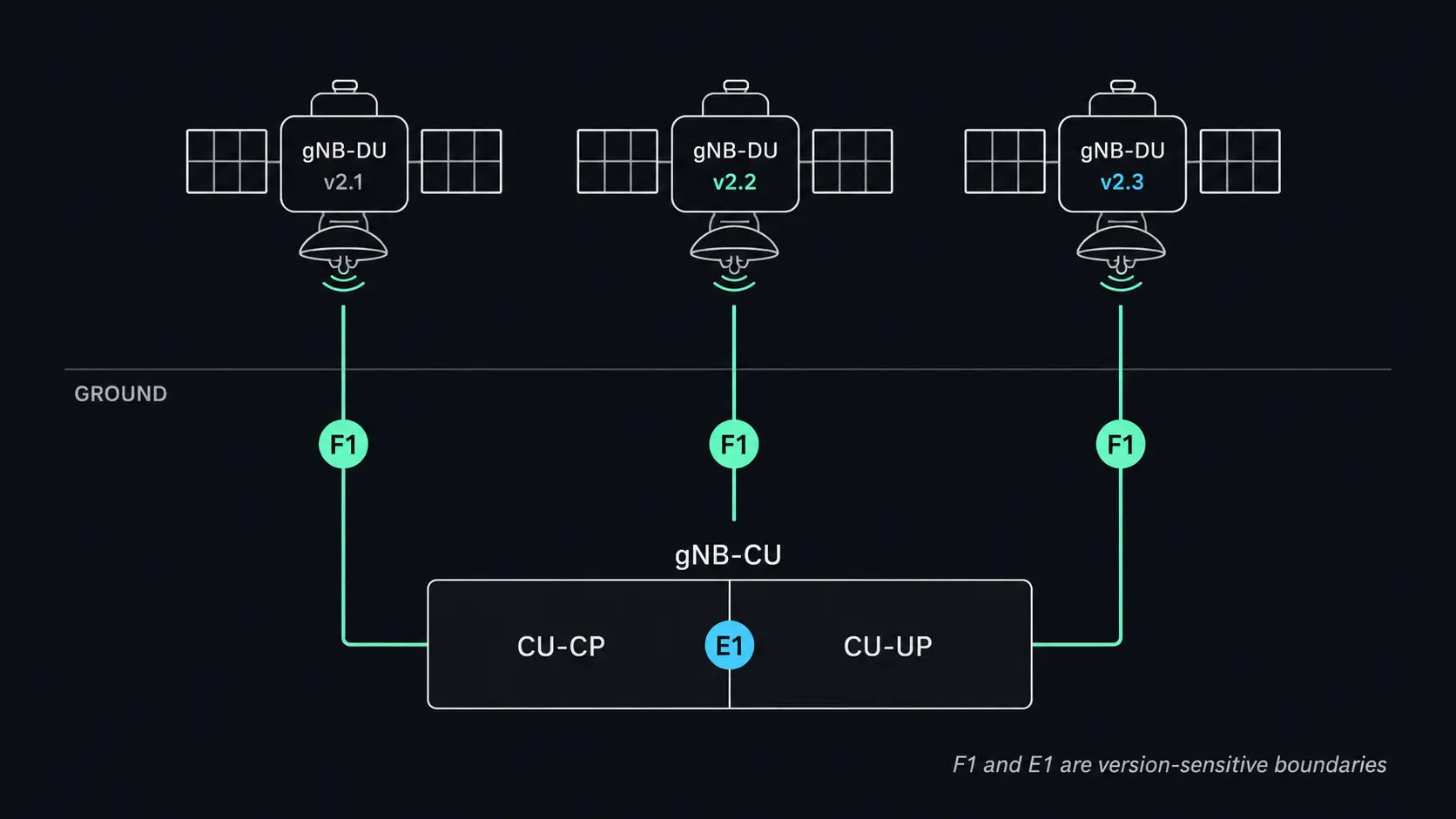
The practical response to these constraints is a combination of rolling update strategies and per-satellite feature gating. New protocol behaviors are implemented but disabled behind configuration flags until a critical mass of the constellation has received the update. Only then are new behaviors activated constellation-wide, or per-region, if coverage overlap permits staged activation.
Rollback in orbit is possible but constrained. Dual-partition boot schemes remain common, allowing reversion to the previous known-good image. Newer payload architectures add containerised process isolation or hypervisor-based fault containment, enabling more granular recovery at the function level rather than a full image swap. In either case, trigger conditions must be carefully defined. A satellite that rolls back during a service window may disrupt active UE connections. A satellite that fails to boot the new image and cannot autonomously revert becomes a dead node until the next TT&C contact, which may be hours away for a LEO satellite outside ground station coverage.
The ground segment must therefore track, per satellite: current software version, hardware revision, active feature flags, and rollback state. Mobility management, load balancing, and handover decisions must account for capability differences. This is not optional complexity. It is the operational baseline for a maintained regenerative constellation.
Gatehouse perspective
Working directly with NTN protocol stacks, we see how changes in one layer interact with assumptions elsewhere in ways that are difficult to predict from specification review alone. A MAC scheduling change that is locally correct can alter HARQ retransmission patterns in a way that stresses RLC reassembly timers or shifts RRC inactivity behavior. These interactions are reproducible in integration testing when you run mixed-version nodes against realistic delay and Doppler profiles, but they are invisible if your regression suite only validates single-version, single-node behavior.
Our experience with version coexistence testing, running different release combinations across simulated constellation segments, confirms that the inter-version boundary is where issues concentrate. Not within a single node running new code, but at the handover, at the F1 interface, at the point where two nodes with slightly different interpretations of timing or scheduling must cooperate on a shared UE context. Designing for this from the outset, defining version compatibility contracts, building regression matrices that cover release combinations rather than individual releases, and instrumenting protocol-layer interactions for cross-version monitoring, is not overcaution. It reflects what we observe when these constraints are encountered without preparation.
Conclusion
The defining challenge of software lifecycle management for regenerative NTN payloads is the sustained coexistence of multiple software revisions across a constellation that cannot be atomically updated, where protocol-layer behavior must remain consistent enough to preserve UE experience across inter-satellite handovers, and where rollback options are real but not free. Teams that treat lifecycle management as a post-deployment operational concern will encounter these constraints through service impact. LEO lifetimes of three to five years provide a natural refresh cycle that eventually retires the oldest hardware, but within that window, the architecture decisions, validation strategies, and ground segment designs that accommodate mixed-version operation need to be in place. They need to be made before the first satellite reaches orbit.
TL;DR for non-engineers
When a satellite carries its own cellular base station software (a “regenerative payload”), updating that software after launch works nothing like updating a cell tower on the ground. You can’t send a technician. Upload bandwidth is tiny. And you can’t update all satellites at once – it takes weeks to roll a single update across a constellation.
That means at any given time, different satellites are running different software versions. This is normal, but it creates a real operational challenge: when a phone moves between two satellites running different versions, the handover has to work cleanly despite differences in how each satellite handles timing, scheduling, and connection management.
The engineering answer is controlled rollouts, feature gating (turning new capabilities on only after enough satellites have the update), and rigorous testing across version combinations. The architecture answer is designing for mixed-version operation from the start, rather than treating it as something to figure out after launch.
For programme and delivery leads, this means lifecycle management needs to be part of the architecture and ground segment design from day one, not a post-deployment operational concern. For leadership, the key takeaway is that the investment case for a regenerative constellation must account for sustained software governance, not just the initial deployment.